

 Table 1: "Web 10." to "Web 20." Paradigm Shift
Table 1: "Web 10." to "Web 20." Paradigm Shift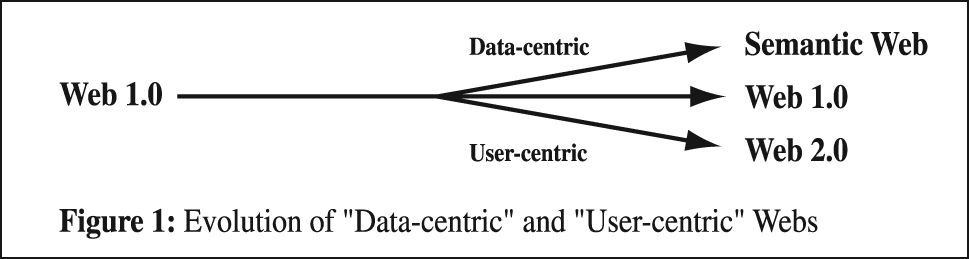
The term, coined by O’Reilly and Associates to publicize a series of conferences, does not suggest a new version of the Web, but simply a marketing phrase for the well-known Sebastopol, California book publisher. O’Reilly has, in fact, threatened legal action against other conference organizers choosing to use a “Web 2.0”reference.
However, whether it is referred to as “Web 2.0”or not, there is a new direction for Web applications and services occurring that promises to affect Web design and development in the future. The results of this direction (I hesitate to say revolution) has been described as “the Living Web and “putting the ‘We’ in the ‘Web.’”
DEFINITION OF WEB 2.0
Before attempting to define “Web 2.0,”it is probably more useful to describe what it is not.
-“Web 2.0”is not the same as the Semantic Web, a model of the future Web described by the World Wide Web Consortium (W3C). There are, however, some shared technological concepts and goals.
-“Web 2.0”is not a collection of new Web technologies. Instead “Web 2.0”applications are more likely innovative applications of existing technologies and techniques.
-“Web 2.0”is not simply blogs, wikis, and RSS (Really Simple Syndication). It is true, however, that these applications have contributed a great deal to the overall perception of “Web 2.0.”More accurately, “Web 2.0”can be described as a change in “Web attitude” that shifts the focus of Web-based information from the creator/author of that information to the user of that information. In order to affect this ‘attitude shift’
- Information moves ‘beyond’ Web sites;
- Information has properties and these properties follow each other and find/establish/define relationships;
- Information comes to users as they move between Web-enabled devices and applications;
- To accomplish these ends, information is defined into units of ‘microcontent’ capable to being distributed over multiple application domains.
In order to take advantage of this new information model, users must be able to more closely control how Web-based information is categorized and manipulated. This requires the definition of new tools for the aggregation and remixing of “microcontent” in new and creative ways. Such tools should be concentrated in the user agent resulting in a “fat” rather than “thin” client model. The presence of such tools in the client suggests a far “richer” user experience and interaction capabilities than are typically available with (X)HTML. Implementations of such “rich user interfaces” in current “Web 2.0”applications are accomplished using technologies such as Flash and AJAX.
It could be argued that this “user-centric” model of the Web is just as consistent with the evolution of the technology as the “data-centric” model represented by the Semantic Web (Figure 1.)
EVOLUTION OF WEB 2.0
The emergence of “Web 2.0 attitudes” can be traced to the time period following the “dot.com crash” in approximately 1999-2000. It has been suggested that these attitudes resulted from a philosophical examination of the overall usefulness of Web technology given the failures experienced at that time. The volume of information and data sources on the Web had reached a “critical mass” and search engine technologies were grappling with the problem of making the Web searchable. At the same time, Web users had developed an expectation of fulfilment and trust. Simple mechanisms such as Google’s “I’m Feeling Lucky,” Amazon’s personalization features, and eBay’s ratings systems addressed some of their user’s basic needs and expectations at the time. Many of the most successful Web companies at that time (e.g., Google, Amazon, eBay, etc.) could be described as embodying a convergence of ‘individual traits and social and technological forces.’ The introduction of blog and wiki technologies during that time period served to further support strong user involvement in the future direction of the Web.
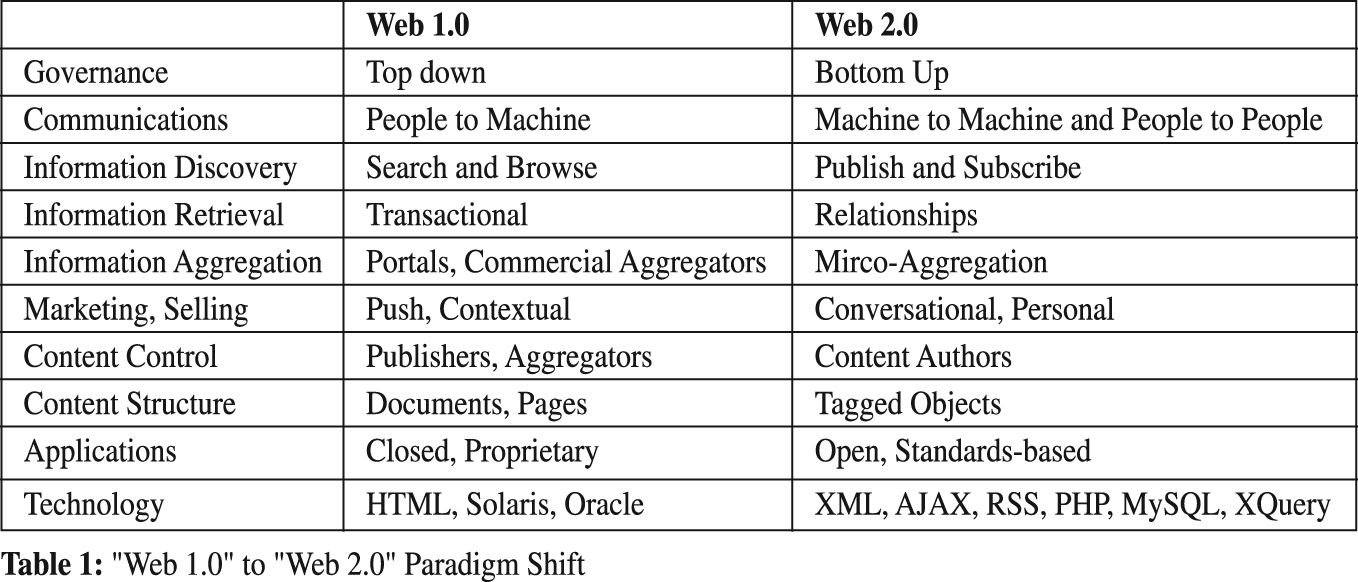
Tim O’Reilly cites the basic paradigm shifts that he observed during this time frame from the existing application of Web technology (unfortunately referred to as “Web 1.0” to the new user-centric “Web 2.0”(Table 1).
The technology shifts shown in Table 1 help to define the fundamental characteristics of a “Web 2.0”infrastructure.
1. “The Web as a Platform” - the familiar model of the Web as a client server application limits its functionality. The Web instead needs to become a distributed system of services and applications integrated as a software platform.
2. “The Web as a Point of Presence”-“Web 1.0”perpetuates the model of “visiting Web sites” “Web 2.0”emphasizes the popular notion of a user navigating through and becoming immersed within ‘cyberspace’
3. “A Web composed of Microcontent”- information defined in terms of microcontent supports an open, decentralized, bottom-up, and self-organizing infrastructure.
4. “A Web of MetaContent” - the content of Web sites, services, etc. should be meaningful ‘Out of context’ and viewed as ‘re-usable objects’ for applications not intended by the content authors/creators.
5. “A Semantic Web” - a Web of objects connected by rich and meaningful semantic relationships.
KEY ELEMENTS
“Web 2.0”adds three new data elements not previously emphasized in the Web information model:
- The “Long Tail”
- Collective Intelligence
- Data Re-use
The “Long tail” refers to the belief that the majority of truly relevant and important information available on the Web resides not on the large, prominent, well-known Web servers, but on many smaller servers and in smaller database systems. The ability to “tap into” this lesser-known source of data can add great value to a Web information system.
”Collective intelligence” refers to the value that users add to existing data on the Web supported by an ‘architecture of participation’. What began philosophically with user ratings on sites such as Amazon.com and eBay has evolved into sophisticated folksonomies - user alternatives to the rigid formalisms of taxonomies. Such collaborative categorization of Web sites using freely chosen keywords (tags) supports rich retrieval methods generated by user activity.
Such “user tagging” is best demonstrated by the impact it has had on Web-based social networking. Popular services such as del.icio.us, Flickr, and LinkedIn are but a few “Web 2.0” instances based upon “user tagging” and linking.
”Data re-use” has led to some of the most exciting and provocative applications of “Web 2.0” By providing APIs (application programming interfaces) to their databases, organizations such as Google and Yahoo have enabled some of the most creative Web applications in recent times. “Mash-ups” are examples of “programming on the Web” where the data streams come from rich sources such as Google maps or Yahoo databases. The result has been applications of the data that the creators could have never anticipated.
WEB 2.0 AND WIS
The scope of Web Information Systems (WIS) can be described as:
- Web information modeling;
- Web information representation, storage, and access;
- Web information extraction;
- Web information mining.
The basic presumption in WIS is that Web technology can be used as a ‘front-end’ to an online information system (e.g., application is available on the Web via a client/browser, or on the ‘back-end’ by means of a Web server or service and/or by using a Web protocol (e.g., HTTP, SOAP, etc.). As a result, most WIS implementations are database driven, require rich, expressive user interfaces, and typically support volatile and dynamic data.
Some of the techniques that have evolved in the definition of “Web 2.0”such as rich interfaces, “user tagging” and database APIs for “data re-use” have great potential in advanced WIS applications. WIS developers and designers should explore the innovations being implemented by the so-called “Web 2.0”applications.